Here’s a cute idea to spice up your days on the command line. Give yourself some regular inspiration, food for thought, or tips and tricks by dishing out a quote each time you open the terminal. This post will show you how you can do this really easily using Python and the Twitter API with zero prior knowledge.
Follow along with the Jupyter Notebook version of this post here.
1: Set up your twitter API
You’re going to need to set up a Twitter app (and an account if you don’t have one) to get your credentials for accessing the API. This step will probably take the longest, but it should just be a few minutes.
Once you have them, for our purposes let’s just store them in a JSON file keys.json like this:
{
"api_key": "api_key_here",
"api_secret": "hello_im_the_api_secret",
"token": "i_am_a_token",
"token_secret": "token_secret_in_the_building"
}
This is maybe not robust security practice, but should be fine for our personal use. Don’t do anything crazy like put that file on github.
You will also need to pip install tweepy.
2: Scrape some tweets
Where should we get our quotes? Twitter can be one great source. I like to use the account CodeWisdom as a source of inspiring, thoughtful quotes about programming and software development in general. One of the other beautiful things about Twitter is the vast amount of pedagogical accounts. The legendary John D. Cook runs a number of them, like UnixToolTip. Inspired by the spaced repetition learning technique, getting some quick tips, tricks, and use cases about unix every day can help you learn some new moves in the command line.
Let’s get all tweets from these two accounts since the beginning of time. Thanks to tweepy, this is really easy! First, do the boilerplate: load up keys and set up the API object:
import json
import tweepy
def load_keys(key_file):
d = json.load(open(key_file, 'r'))
return d['api_key'],d['api_secret'],d['token'],d['token_secret']
api_key, api_secret, token, token_secret = load_keys(KEY_FILE)
auth = tweepy.OAuthHandler(api_key, api_secret)
auth.set_access_token(token, token_secret)
api = tweepy.API(auth)
Now we’ll use tweepy’s user_timeline method to retrieve all the tweets for a user. Due to rate limits (I’m guessing), only up to 200 tweets can be returned at a time, so to get the whole timeline, we’ll keep sending requests, using the last tweet ID we got as the max_id input, to let the API know where we want the new results to start. This makes the code a little non-trivial, but hey, we’re not here just to mess around:
def get_tweets(api, root_user):
tweets = set()
#get the first set of tweets (you really need a set, because for these accounts some might be repeated)
print("sending initial request...")
results, oldest_id = retrieve_tweets(api, root_user)
tweets.update(results)
#now, go back through the remaining history
while len(results) > 0:
print("tweets so far: %d. sending request..." % len(tweets))
results, oldest_id = retrieve_tweets(api, root_user, max_id=oldest_id-1)
tweets.update(results)
print("total tweets: %d" % len(tweets))
return tweets
We also should probably exclude tweets with links and retweets, and we can limit to the most popular tweets if we like.
def retrieve_tweets(api, root_user, max_id=None):
tweets = []
results = api.user_timeline(id=root_user, count=200, max_id=max_id)
for result in results:
#exclude tweets with media
if 'media' not in result.entities:
#exclude replies and RTs (RTs fall under user mentions), tweets with links, and unpopular tweets
if len(result.entities['user_mentions']) == 0 and len(result.entities['urls']) == 0 \
and result.favorite_count > 30:
#get rid of some html artifacts and put each tweet on one line
tweets.append(re.sub('\s+', ' ', hparser.unescape(result.text)))
oldest_id = results[-1].id if len(results) > 0 else None
return set(tweets), oldest_id
Now we just have to use these methods to scrape and save our tweets to file:
tweets = get_tweets(api, 'CodeWisdom')
with open('/your/path/here', 'w') as outfile:
for tweet in data:
outfile.write(tweet + "\n")
3: Update your .bashrc
Now that we have our adages, aphorisms, maxims, and quotes, just throw this line at the end of your shell startup script and we’re done! Bonus points for adding a pipe into cowsay.
cat ~/tweets1 ~/tweets2 | shuf -n 1
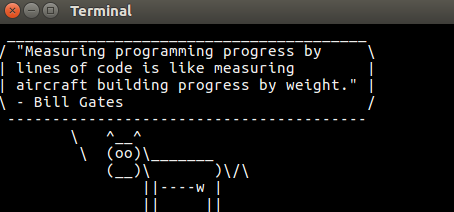
Yeehaw!